Knowledge Graphs, Machine Learning and Heritage Collections
Kalyan Dutia
As part of the Heritage Connector project we’re seeking to create new links between collection items and collections at scale by making use of existing metadata and mining structured data from text, as well as using Wikidata as a centralised point of connection between collections. These challenges require a set of technologies beyond those found in existing collections management systems. This blog post describes exactly which technologies we’re using and how we’re using them.
If you’re familiar with knowledge graphs, feel free to skip to how we’re creating new links.
Contents:
Knowledge Graphs
Knowledge graphs were popularised by Google in their 2012 blog post Introducing the Knowledge Graph: things, not strings, in which they described how data structured in a graph (rather than a table) can help users get better responses to their queries, retrieve context around a specific object, and even discover new serendipitous connections between objects. These things can be achieved using Knowledge Graphs as they let you create new links (relations) between items (entities) without worrying about creating specific columns or tables to hold information.
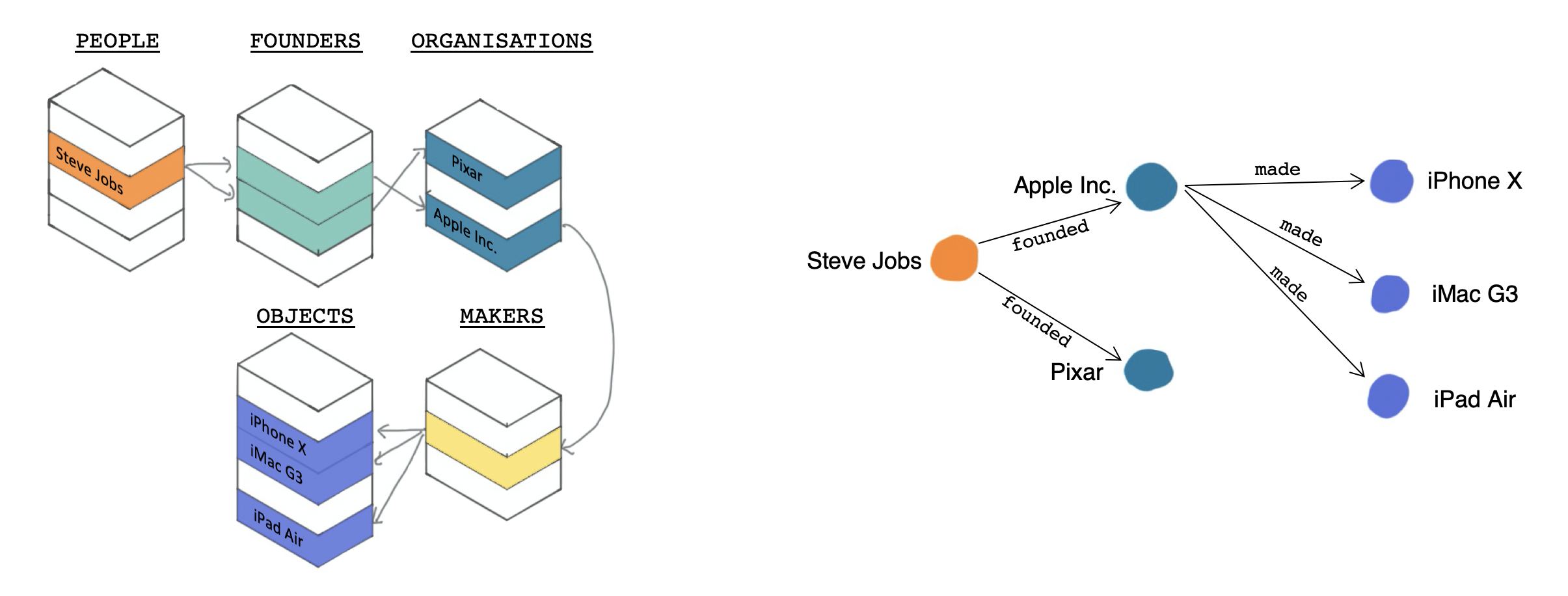 Representation of Steve Jobs’ legacy in complex relational database format (left) and simpler knowledge graph format (right)
Representation of Steve Jobs’ legacy in complex relational database format (left) and simpler knowledge graph format (right)
The knowledge graph is what we refer to when we talk about the ‘Heritage Connector’ itself: one place where all connections (from 13 data sources and counting) between the internal tables that make up our digital collection live, and where we can add new entities and relations as we discover them.
The specific flavour of knowledge graph we’re using called a triple store, because every relationship is expressed in three parts: a subject, a predicate and an object. This representation has been chosen because any fact can be represented as a triple at its most granular level. For example, we store “Marie Stopes was born in Edinburgh” as (marie_stopes, born_in, edinburgh), and “Rover ‘Safety’ Bicycle was designed in 1885” as (rover_safety_bicycle, designed_in, 1885).
To make our graph interoperable with other data sources we’re building this graph to abide by Linked Data standards, namely:
- Using HTTP URIs (web addresses) so that entities can be looked up
- Providing useful information, where we can 1, when these entities are looked up
- Refer to other things, external to the collection, by their HTTP URIs
 Comparing raw text, semantic triples and triples that meet Linked Data requirements
Comparing raw text, semantic triples and triples that meet Linked Data requirements
Creating New Links
We’re building and evaluating three main methods to create links internally and to Wikidata:
- easy wins: converting existing URLs and IDs in the collection to Wikidata IDs,
- machine learning for creating new links between the SMG collection and Wikidata, and
- named entity recognition (NER) for creating internal links: adding new entities to the graph from free text fields.
It’s important to note at this point that we’re not aiming to link each and every record up to Wikidata - that would be impossible, as many SMG people, organisations and objects will not have Wikidata referents. Instead, our aim is to use information from Wikidata through the creation of links where possible, and focus on creating structure in the Heritage Connector that we can contribute back to Wikidata at a later date.
Easy Wins (Existing IDs)
 Steps in the process to generate Wikidata links from existing IDs and URLs found in the Collection.
Steps in the process to generate Wikidata links from existing IDs and URLs found in the Collection.
Around 10,000 records 2 in the SMG collection have had IDs or URLs from databases like Oxford Dictionary of National Biography, Grace’s Guide or Wikipedia added to them in the museum’s collection management system (Mimsy). Wikidata holds references to external databases using External IDs 3, making it straightforward to convert an external reference to a Wikidata ID. For example, a SPARQL query can return the Wikidata page that has the Grace’s Guide ID Isambard_Kingdom_Brunel.
We’ve found that there’s one more step to ensure these connections are accurate. As well as an ID that relates to the record, curators regularly add IDs or URLs to related entities in the Notes field of a collection item, e.g. someone’s father or company. To ensure that each link is accurate we’ve added an extra step to the process which checks that the labels and significant dates (e.g. birth/death date) are similar for both the SMG and Wikidata entity if they are both present.
Disambiguation
Broadly speaking, the disambiguator is a tool which learns to distinguish whether an internal (SMG) record and a Wikidata record refer to the same real-world entity. Using machine learning this enables the creation of links between internal SMG records and Wikidata records faster than any human could, with a measurable accuracy.
There are a few deep learning 4 based methods 5 6 which use tools like knowledge graph and word embeddings to perform this disambiguation. But they tend to require large numbers of data to perform well (in the order of thousands), and knowledge graph embeddings require a graph representation which captures some ‘structure’ of the information (which we didn’t have, due to thin records). For this reason we chose to use a classical machine learning method, which requires much less data and computational power.
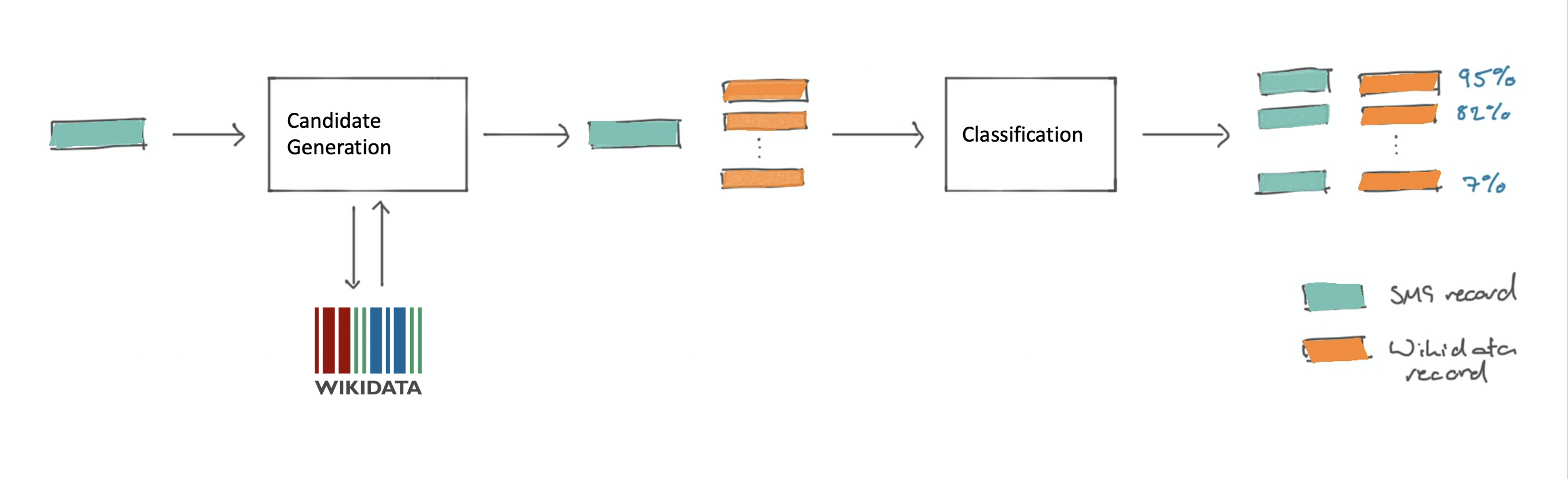 Illustration of Disambiguation process. Colours below refer to the coloured blocks on this figure.
Illustration of Disambiguation process. Colours below refer to the coloured blocks on this figure.
The disambiguator works as above, with the steps Candidate Generation and Classification as follows.
Candidate Generation
- Select an SMG record to find a Wikidata match for
- Search the label/title of this record on Wikidata 7 returning the N top matches, where N is a value that has been chosen beforehand (we chose 20).
Classification
- Compare each field in the SMG record to its corresponding field in each Wikidata record using the Heritage Connector’s similarity function which can compare strings, numbers, dates, places and entity types. This will produce N vectors, each containing F feature similarities between 0 and 1.
- Run the vectors through a machine learning classifier, for either training or inference. A training run will produce a disambiguator capable of operating on a dataset. An inference run will predict whether a pair of unseen records represent the same real-world entity, returning a confidence value for the link.
Named Entity Recognition (NER)
NER is a natural language processing (NLP) technique which aims to find words (entities) in a piece of text which are of a number of predetermined types. It does this by learning both what these entities of a type tend to look like and where they tend to appear in a sentence.
In the example below NER has been run on the SMG description of the Difference Engine No.2 to detect people, dates, organisations and works of art.
 Example of Named Entity Recognition on the SMG description for Difference Engine No. 2
Example of Named Entity Recognition on the SMG description for Difference Engine No. 2
By training an NER model on types of entities that we’d want to add to the Heritage Connector, for example people, places, historical events or movements, we have a method to add new typed entities to the knowledge graph from unstructured text.
Robustly extracting relations between entities is harder: existing methods for relation extraction 8 haven’t proved reliable in tests on our data. This is mainly due to their wide-domain application. Later on in the project we plan to research methods for reliably extracting relations from text and aligning them with RDF predicates for application in the heritage domain.
Results, Lessons and Next Steps
Currently (November 2020) in the project we’ve just finished building mechanisms to load in tabular data to a knowledge graph, load links from external IDs, and the disambiguator. We’ve tested the disambiguator on people, organisations and objects.
Some of the things we’ve learnt so far are:
- Aligning specific free-text fields to entities (in our case collection item types and locations) is important, but can take a while using existing tools such as OpenRefine. Faster and more robust methods therefore exist in the Heritage Connector.
- You can expect varying success disambiguating records with Wikidata depending on their type, due to the nature of the records in Wikidata. We’ve had most success with people and organisations and expect that we’ll be able to find Wikidata links for a much smaller proportion of objects as they are less likely to exist on Wikidata.
- Although we’ve presented the steps of creating a linked knowledge graph as sequential, in reality they work better in a kind of loop. As you use NER to create more entities and relations in the graph, the effectiveness of the disambiguator will increase.
- Where possible it’s best not to bulk query Wikidata, especially through SPARQL. We’ve circumvented this by creating an Elasticsearch index we can use to perform text searches on Wikidata in a faster and more stable way. We’ve open-sourced the tool we used to do this as elastic-wikidata.
And next, we plan to:
- Start looking at how knowledge graphs enable new forms of interaction and discovery in practice.
- Build and test a robust NER method for the heritage domain. We’ll open source any heritage-specific models that we create using the popular Spacy NLP library so they can be used for any NLP applications in the heritage sector.
- Write more blog posts!
Footnotes
-
Wikidata helps with this ↩
-
Mainly people and organisations, not objects. Disambiguating objects is the main challenge we’ll have due to the broadness of the category ‘object’ and our lack of training data. ↩
-
We’ve created one for the Science Museum Group for this project, and would recommend the same practice for all heritage organisations looking to link to Wikidata. An example of its use is on this Hindu Astrolabe. ↩
-
A class of machine learning methods which use ‘deep’ neural networks with multiple layers. See Wikipedia ↩
-
Farag, M., 2019. Entity Matching and Disambiguation Across Multiple Knowledge Graphs ↩
-
Mudgal, S. et al., 2018, May. Deep learning for entity matching: A design space exploration. In Proceedings of the 2018 International Conference on Management of Data (pp. 19-34). ↩
-
We created the elastic-wikidata tool to load the labels, aliases, descriptions and types a useful subset of Wikidata into our own Elasticsearch index to speed up text searches. ↩
-
Gangemi, A. et al., 2017. Semantic web machine reading with FRED. Semantic Web, 8(6), pp.873-893. ↩