History, AI and Knowledge Graphs
A conversation between Tim Boon and Kalyan Dutia
Tim: Let’s start by explaining why we’re here and who we are. The Science Museum Group has a current research project, Heritage Connector, which is bringing the power of modern computing to address some long-standing issues to do with how we record information about the objects in our collections. One way of describing the aim of the project is that we want to make it easier for people to find and appreciate these millions of objects, pictures and documents.
I come to this as a Science Museum curator and historian with several decades’ experience of the collections. I’ve enjoyed building-up understanding of the collections over the years, but also shared the frustration of many people that it’s so difficult to gain access to our collections and what they mean via the tools we have available: our catalogues and their online incarnation as collections online. What’s been really exciting me about Heritage Connector is that I get a real glimpse of a solution to that problem.
Kalyan: I came to this project from a completely different perspective: before working on Heritage Connector, I was a private-sector AI consultant helping companies improve their business processes with natural language processing. I remember first seeing the description of the project and thinking it was a great issue for a museum group to be tackling, both as a technologist and lover of museums and galleries.
Over the first nine months of the project, I’ve gathered that a major motivation for this work from inside the museum is that although cataloguing of digital collection records is of good quality when it’s there, often records have very little metadata. This sometimes leads to difficulties when trying to navigate the online collection. Tim, could you tell me more about how this problem came about and the particular pain-points you think a project like Heritage Connector could help to solve?
Tim: Well, in 1984 the Museum switched-on its first mini-computer, purchased with the plan of centralising in machine form all the catalogue information to do with our object and library collections. Up until then, for more than a hundred years before, the Museum had used paper records – ledgers, files and cards – to store its collections records. The curators and their assistants had in their offices sets of ‘forms 100’, small index cards, each one of which recorded the basic details of each object. There would be a little filing cabinet for each collection. Here’s an example:

You can see that the information is quite rudimentary; an inventory number, a description, source and date, file number, locations (often with many updates from over the years, along with other miscellaneous pencilled notes). To create the computer database, data processors typed-in the details from these cards. Only the typed information was entered into the database. In other words, the source of the information we use today was basic audit tools; these cards were the everyday working tools of people who had to be able to locate the objects in their care whenever they were needed to answer an enquiry or to be placed on display.
Where was the contextual information that made sense of this? Well, very often it was in the curator’s head; these people were employed to understand, and to develop their understanding of, the fields they were responsible for – in this case, communications. The ‘registered paper’ cross-refers to a file held within the Museum’s Registry, and more information would often be held there. And, eventually, a description of an object would be printed in the Museum’s published catalogues, and might feature in the historical handbooks which, collection by collection, the Museum used to publish.

You ask me what particular pain points I think ‘Heritage Connector’ could help to solve. At the top level, I think we’re looking to use computing techniques to overcome the unsuitability of the records we have to the needs of today. We can see that the systems that curators used in the past were fine for that world, in which it was the job of experts to mediate all the information about the collections. But in our information age, people expect to be able to access what we hold, and what it means. It’s a huge job to make that possible, but I’m optimistic that computing techniques can do some of the heavy lifting. The precise ‘pain point’ is that the available data don’t say enough about the objects that it’s easy for people to make the kinds of connections that curators carry in their heads. So, at this point, Kalyan, could you explain how some of the techniques you are developing in ‘Heritage Connector’ can connect some of the heritage we hold, and to what?
Kalyan: Sure. So, when we look at the picture of the index card above, we can see that most of the information content describing the object is in the Object field, which consists of a few lines of text. The collection records in Collections Online tend to look very similar to this index card, with expressive Description fields containing a few sentences about an object, person or organisation, and very little metadata to describe the object. In other words, there is lots of ‘unstructured’ data in the museum collection which, although searchable by text, can’t be used to do things like search for items using filters, browse related collection records through an interface, or conduct specific research about say a person, place or historical movement.
Through reading the Object field (maybe with some additional Googling) we can figure out that the object in question was used by the Marconi Company, founded in 1897, to perform the first Transatlantic transmission of wireless signals. With the use of some machine learning (ML) techniques, we can perform the same task of extracting named entities (Named Entity Recognition/NER) from text and linking them to some data source such as Wikipedia or Wikidata (Entity Linking/EL). We can also use Record Linkage (or Disambiguation) techniques to link entire collection records to Wikipedia or Wikidata records, in the case that there are things represented in our collection that are also represented on Wikidata.

To store this ‘web’ of links in a relational database (such as the online collection is currently stored in) would be challenging, as creating a new field tends to involve creating entire new columns in different tables, which in turn usually requires significant development effort and/or a few steps of organisational approval. For Heritage Connector we instead use a knowledge graph to store collection catalogue records and the connections between them, in which records and concepts are stored as entities and connected to each other by relations.
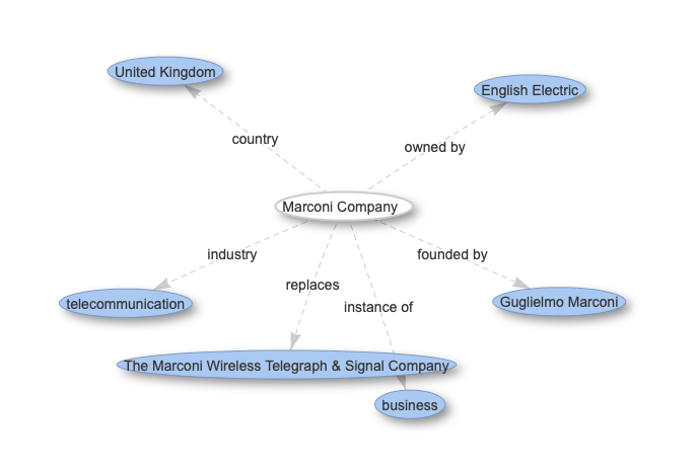
By using NER and EL we can build a knowledge graph containing information that was before impossible to put to use when navigating a collection, without the human effort that would be required to label all these records manually. Further to this, through the knowledge graph being linked to Wikidata we can start looking at multiple collections or datasets together: either through importing and processing them separately (we are doing this in the project with the V&A’s collection), or making use of the links that already exist to other databases through Wikidata. Such links already exist in Wikidata to historical databases through External IDs such as Grace’s Guide, other collections such as the Library of Congress, and other data sources such as Geonames.
Tim: That’s really interesting. We can see that this rather vaguely described example of old items of wireless telegraphy apparatus could be automatically linked to the Wikidata entity for the Marconi Company. If another museum, say the History of Science Museum in Oxford, which looks after the major collection of the Marconi Company, had also linked to Wikidata, then our object would automatically be contextualised by the larger collection. The Bodleian Library, across the road from the museum in Oxford holds the Company Archives; if that was also linked, even at the top level, the researcher would very easily be able to move between an individual object, the larger set of surviving objects, and the archives or literature that could illuminate something of the significance that led the curator to collect the object in the first place. Given that the convention was for the curator to know such things, but not to note them on the form 100, even at this most basic level, the technique is demonstrating value.
I’m interested in the relationship between what these automated techniques could do and the web of understanding that the curator carries in their head. In the paragraph above, I was able to suggest some links because, although I was never curator of the communications collection, over the years I’ve accumulated amongst my miscellaneous curatorial knowledge the fact that the Marconi Collections are held in Oxford. So, my first question arising from this is to ask whether a project that applied NER and EL techniques across records of the nation’s collections would mean that researchers would be less dependent on what curators happen, almost randomly, to know?
My second question is about those places where the terms the curator used are less than clear. The other term that the NER program has found in this description is ‘Trans-Atlantic tests’ as an ‘event’. There is no Wikidata entity for that term. Is that a blind alley for the techniques you are developing, or are there other means to interpret that term and, perhaps, to find other objects associated with Trans-Atlantic tests’? Similarly, the inventory description also uses the term ‘W/T apparatus’. I guessed (with the help of an online search) that this must mean ‘wireless telegraphy’. Is that sort of act of interpretation of jargon something that only humans can do, or are there ways of using computing to make such leaps?
Kalyan: I want to briefly pick up on your description of these ML techniques as ‘automated’ to answer these questions. In practice these tools are great at learning from patterns in data to complete simple tasks: Benedict Evans uses the metaphor that machine learning gives you ‘infinite interns, or, perhaps infinite ten year olds’. As with interns, it’s the job of the team designing and maintaining such a system to continually ensure it has the correct information to complete the task at hand (data). This means that, while we can think of ML tools as automating a portion of work that needs to be done, it’s important to expect and plan for human involvement to maintain and develop them throughout any project that uses them.
This means that your first question can be seen as one about the data that an ML system is trained on: for the system to know about ‘the almost random things a curator may happen to know’, these ‘random things’ must be in the data. In our case that means two things:
- that the data used to train the NER model enables it to cover the topics we need with suitable accuracy, and
- that the collections (and other) data from which the knowledge graph is built contains the concepts that are likely to be needed for planned research.
Of course, it’s unlikely that we’ll get everything we need into the knowledge graph on the first try, so it’s important that we build mechanisms to add-in new data, and also that we retrain the models as and when we need to. You’ve opened my eyes to the fact that we may well benefit from a mechanism where a curator can add facts directly to the knowledge graph too.
Your second question asks about two tasks that we might want the system to perform: discovering a concept in a collection where there is not a Wikidata entity to refer to; and converting technical jargon to standardised terms. Taking the first task as an example, we could build (and are building) a part of the Heritage Connector software that, for a found term:
- first tries to link it to a Science Museum Group (SMG) collection record;
- then tries to link it to Wikidata if no links to SMG records were found;
- then, if there is no existing Wikidata entity for the term, looks to create a new record either in the SMG knowledge graph or in Wikidata.
It’s not immediately clear what the best approach to the final step above is (adding a new record to the SMG knowledge graph vs Wikidata), as it will depend on things such as whether the term is common enough to live on Wikidata, or so specialised that it will be better placed in only the SMG collection, as well as whether it appears one time or 10,000 times in the museum collection.
So, although a machine learning system can complete parts of the above task to a degree of accuracy, there’s a part of it where human intervention is better placed to make such leaps as identifying that ‘Trans-Atlantic tests’ is a concept that appears enough times in collections to merit a Wikidata entity, and to populate the record for this entity in Wikidata.
I hope I’ve demonstrated by example that ML systems are intended to augment researchers’ and curators’ work, rather than fully automating it. As part of the project, we’re exploring where this human involvement is best placed, as well as where any specialist expertise or skills may be required.
Tim: Following your suggestion that human intervention is crucial to success, it is worth giving an example of how this might work. Whilst writing this blog, I contacted John Liffen, the former Curator of Communications, and he was able to supply me with a scan from the Museum’s published 1925 catalogue, written by Roderick Denman the curator who acquired the items in the 1920s:

It turns out, mercifully, that this is one acquisition – however slight the form 100 record – that has in recent years received serious attention; John was able, in preparation for the Museum’s Information Age Gallery, to undertake detailed research on the identity and significance of these artefacts. His account can be read here: Some Early Marconi Experimental Apparatus Reappraised. He was also able to enhance the online information about these artefacts so that, far from the insufficiency we can see on the card reproduced above, the descriptions are now detailed and precise.
It turns out that, if we were to use the ‘Heritage Connector’ NER and EL techniques to link this set of objects to the outside world via Wikidata, that the benefit would flow from the detailed research and cataloguing work carried on at the Science Museum to any other items connected to the relevant Wikidata entries. Unfortunately, this is not the case with the majority of the records for objects in our collection, where the online records are much closer to that form 100. We can look forward though, to many years where ML techniques, assisting detailed research, can help collections to be better understood and appreciated.